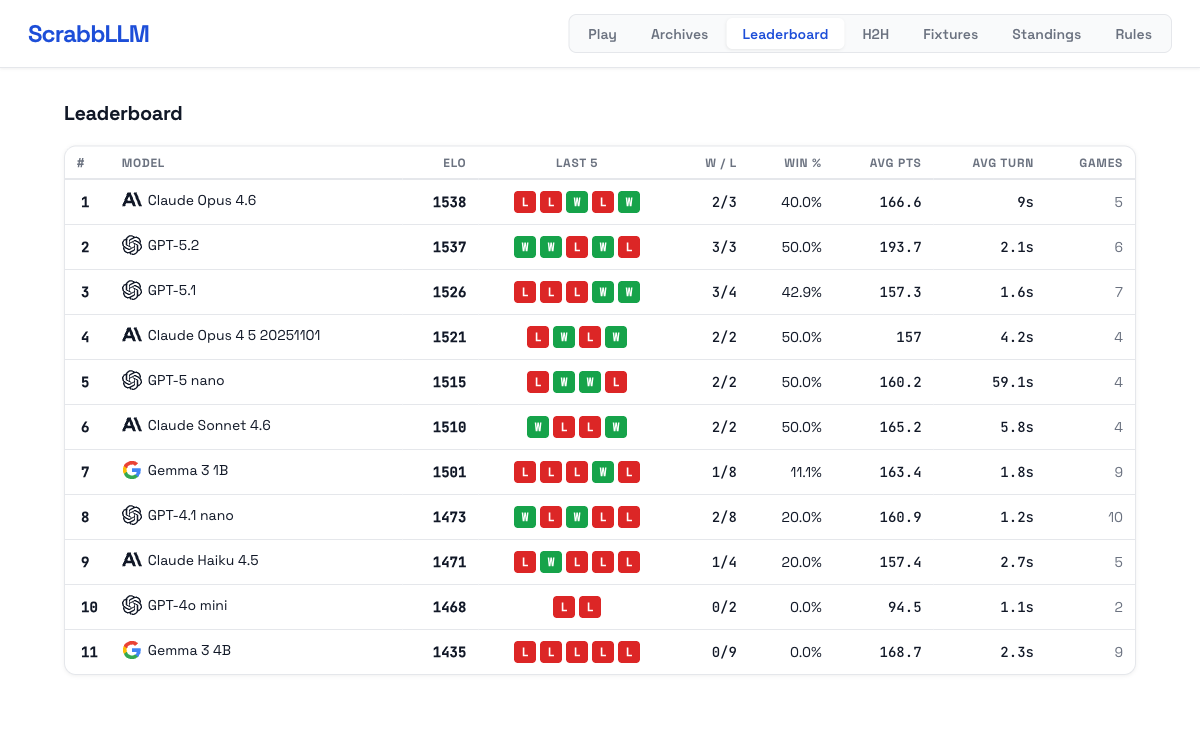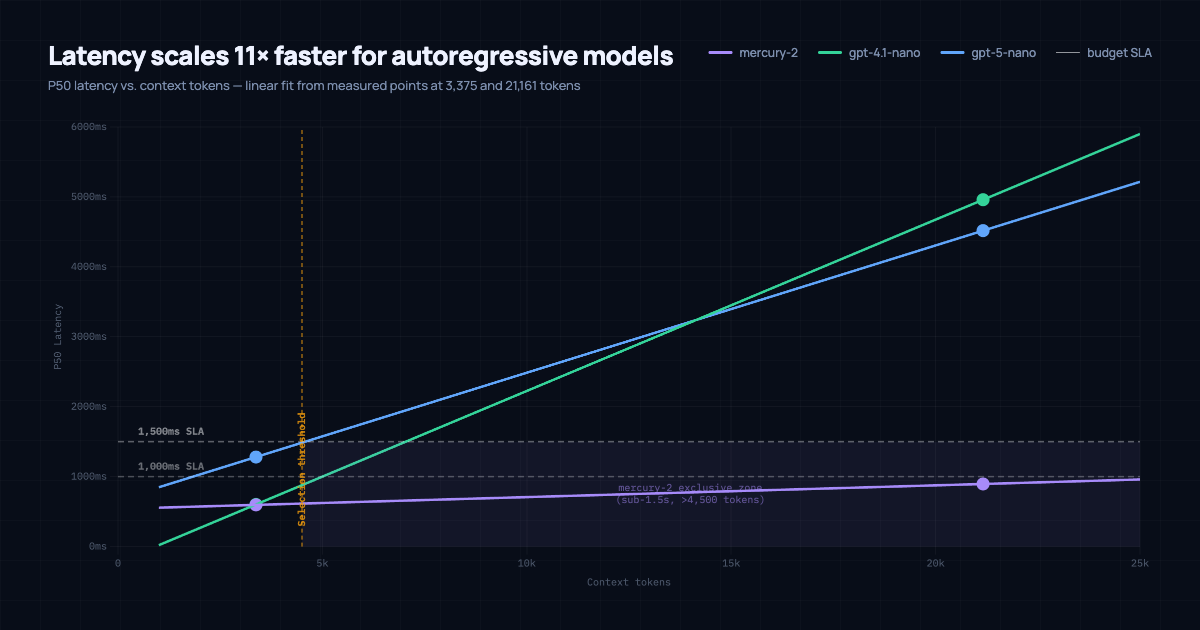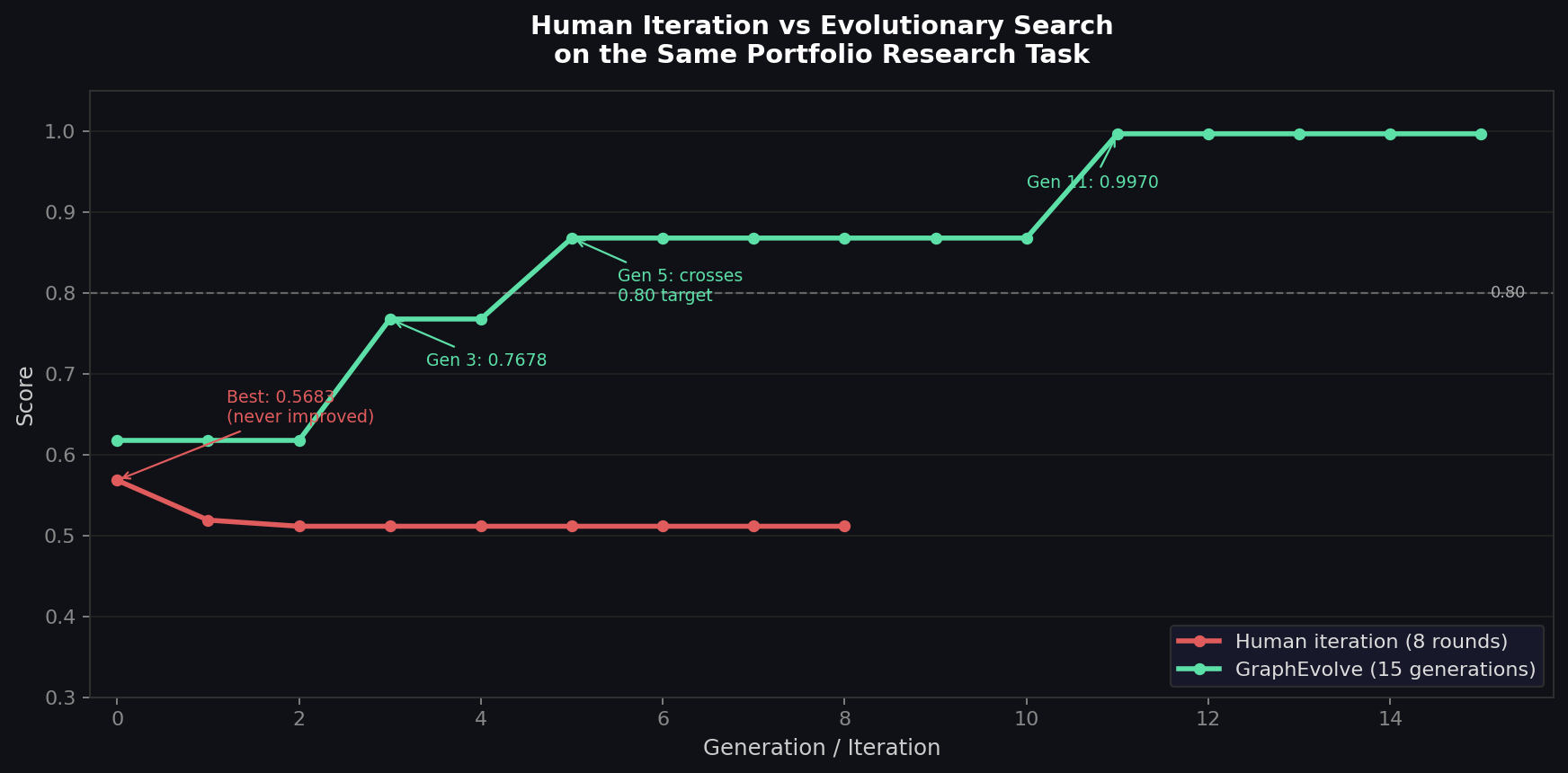
Everything is RL: Automatically Creating Optimal Agents with Evolutionary Methods
· 11 min read


The way most people build software with LLMs today is: write something, look at it, ask an LLM to make it better, look at it again. Vibecoding. It's fast, it's surprisingly effective, and it's still fundamentally local search guided by human intuition.
Human intuition is a bad guide for knowing if something actually got better. You can feel like an iteration was good without having moved the metric that matters. You can iterate eight times and end up with a more sophisticated-looking solution that scores lower than what you started with. I know this because I ran the experiment.