The New Normal? Early Results from InceptionLabs' Diffusion-Based LLM Look Promising


The longer your context, the slower transformer-based LLMs get. It's not a tuning problem, it's architectural: autoregressive models produce one token at a time and attend over the full context on each step. At 20,000 tokens, you're paying for 20,000 tokens of attention on every single generation step.
InceptionLabs' Mercury-2 uses a diffusion architecture that generates output in parallel across the full sequence, so its latency doesn't scale the same way. I benchmarked it against GPT-4.1-nano and GPT-5-nano in a RAG pipeline at two context lengths. At short context, Mercury-2 finishes last on every metric. At 21k tokens, it's 5x faster than the alternatives and the only model that stays under 1.5 seconds. The crossover is around 4,500 tokens.
Background: How Mercury-2 Actually Works
Every LLM you've used, GPT, Claude, Gemini, Llama, is autoregressive. It produces output left-to-right, one token at a time. Each step attends over the full input context. This is fine at short context lengths and terrible at long ones, because the per-step cost grows linearly with how much you've fed it.
Mercury-2 from InceptionLabs uses a diffusion architecture. Instead of generating tokens sequentially, it starts with a noisy draft of the full output and refines it across multiple passes until it converges on a coherent response. The same basic idea behind image generators like Stable Diffusion, applied to text.
The practical difference: Mercury-2's latency is much less sensitive to input length. At 3,000 tokens of context it takes about 600ms. At 21,000 tokens it takes about 900ms. GPT-4.1-nano and GPT-5-nano go from around 600ms at short context to nearly 5 seconds at long context. That gap is what this benchmark is measuring.
What I Tested
The setup: 43 factual Q&A pairs across science, history, and technology. A FAISS retriever pulls the most relevant passages from a 20-document corpus, and the model generates an answer. I measured three things per query:
- Token F1: how well the generated answer overlaps the ground truth, scored SQuAD-style
- P50 latency: the median time-to-response in milliseconds
- Cost per query: computed from token usage at published pricing
Every question ran twice: once with a standard retrieval window (~3,375 tokens of context) and once with long-context retrieval (~21,161 tokens), where the model sees a much larger slice of the corpus before answering.
Standard RAG: GPT-5-nano Wins Across the Board
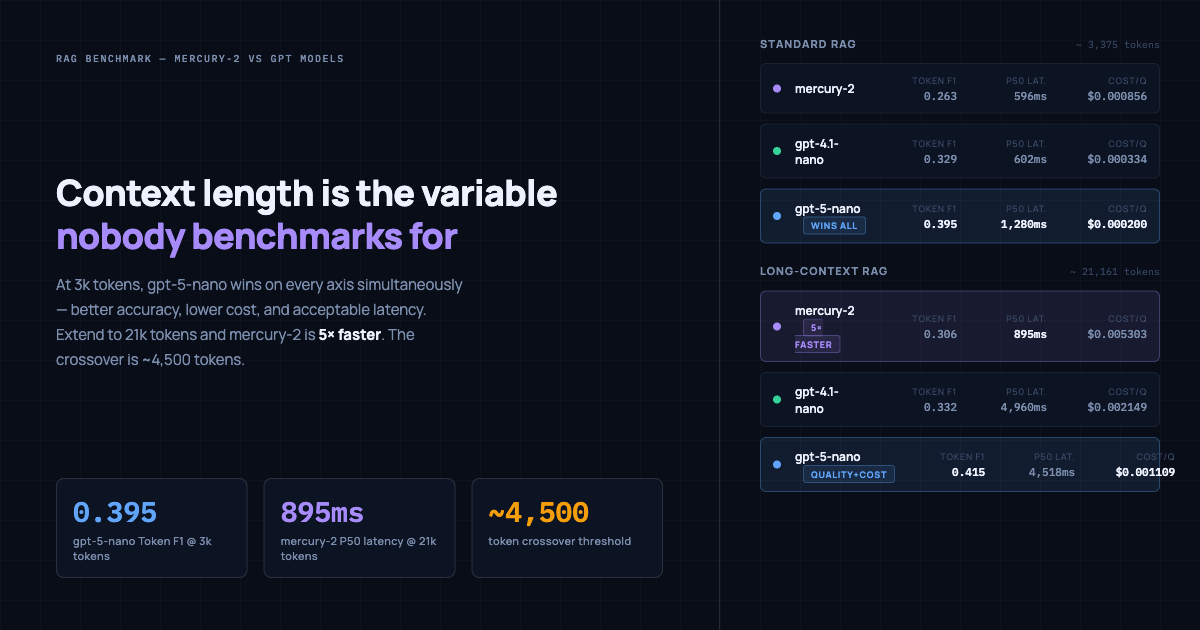
At the context sizes that most production RAG pipelines actually operate at, GPT-5-nano is the clear choice. It posts the highest accuracy, the lowest cost, and a latency that is slower than Mercury-2 and GPT-4.1-nano but still within any reasonable service level agreement.
| Model | Token F1 | P50 Latency | Cost / Query |
|---|---|---|---|
| mercury-2 | 0.263 | 596ms | $0.000856 |
| gpt-4.1-nano | 0.329 | 602ms | $0.000334 |
| gpt-5-nano | 0.395 | 1,280ms | $0.000200 |
GPT-5-nano is 50% more accurate than Mercury-2, 4.3x cheaper per query, and just 678ms slower at the median. For nearly any production RAG use case at standard context lengths, that trade is straightforward.
GPT-4.1-nano sits in the middle: better accuracy than Mercury-2, lower cost than Mercury-2, and roughly equivalent latency. At standard context, there is no dimension on which Mercury-2 wins outright.
Long-Context RAG: The Picture Inverts
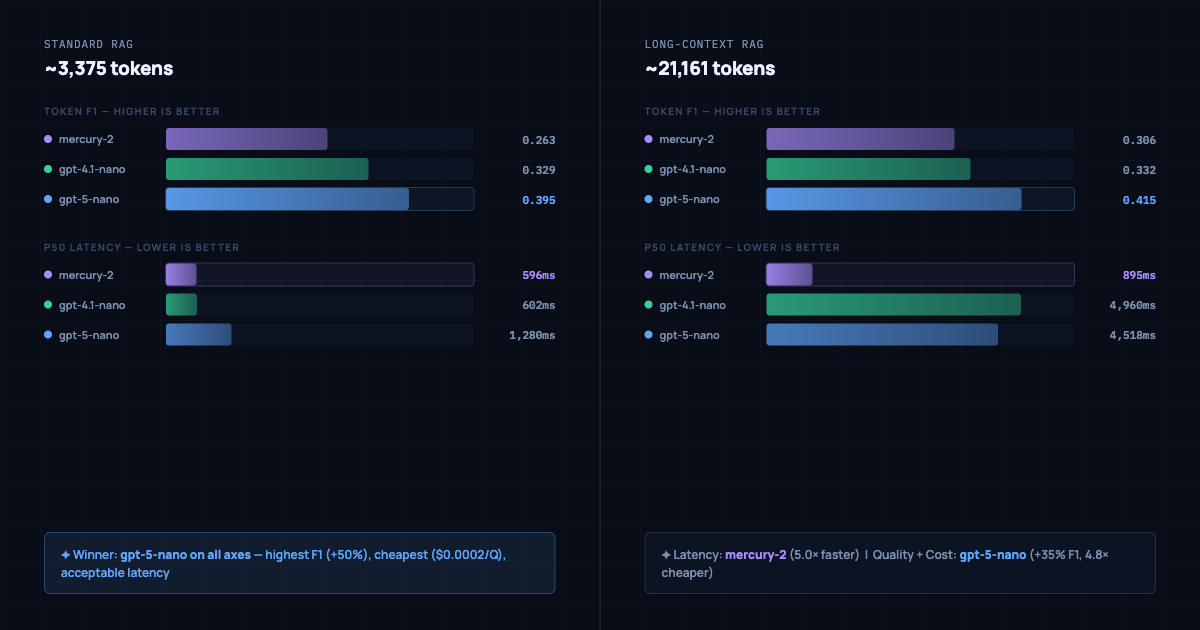
Extend the context window to roughly 21k tokens and everything changes. This is the regime that matters for full-document retrieval, multi-hop reasoning, or pipelines that pass large corpus slices to the model.
| Model | Token F1 | P50 Latency | Cost / Query |
|---|---|---|---|
| mercury-2 | 0.306 | 895ms | $0.005303 |
| gpt-4.1-nano | 0.332 | 4,960ms | $0.002149 |
| gpt-5-nano | 0.415 | 4,518ms | $0.001109 |
Mercury-2's median latency barely moves. It goes from 596ms at 3k tokens to 895ms at 21k tokens. GPT-4.1-nano and GPT-5-nano climb to nearly five seconds each. Mercury-2 is 5x faster than both alternatives at long context.
The architectural explanation is straightforward. Autoregressive models pay a per-token processing cost on every token in the input, and that cost accumulates linearly as context grows. Mercury-2's diffusion architecture generates output in parallel passes over the full sequence, so its latency is much less sensitive to input length.
Accuracy and cost still favor GPT-5-nano for teams willing to absorb the wait: F1 of 0.415 versus 0.306 for Mercury-2, at roughly 4.8x lower cost per query.
The Crossover Point: Around 4,500 Tokens
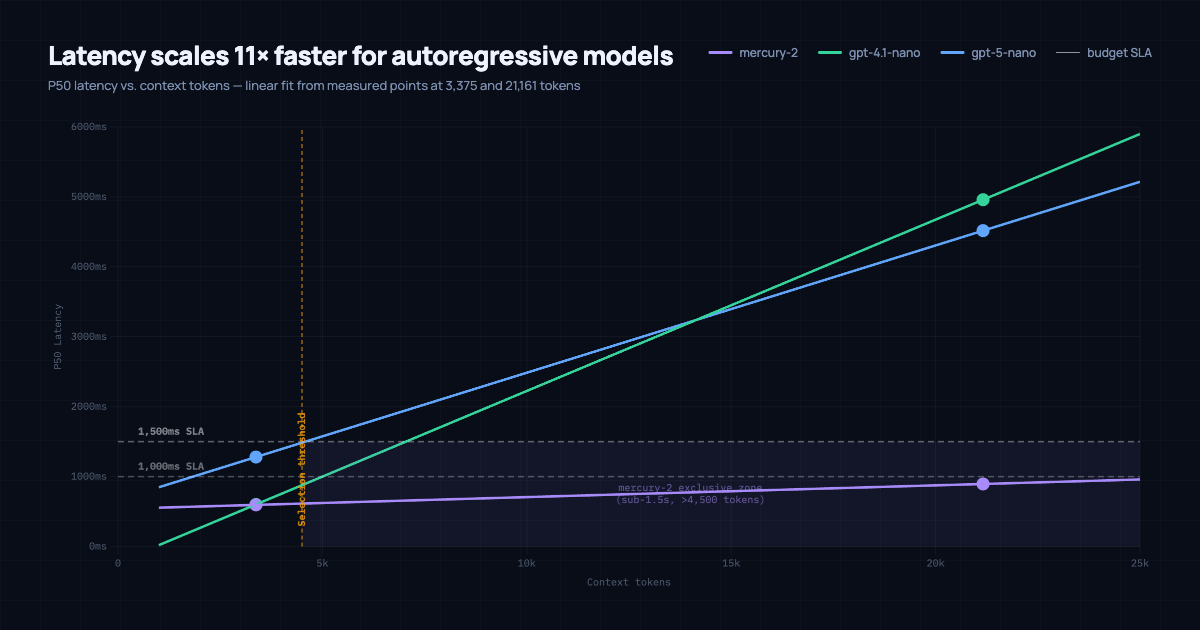
The scaling chart makes the trade-off concrete. Mercury-2 scales at 0.017 ms per token. GPT-5-nano scales at 0.182 ms per token, roughly 11x steeper growth. The two lines cross at approximately 4,500 tokens.
Below that threshold, GPT-5-nano's more favorable base latency keeps it under a 1,500ms SLA. Above it, only Mercury-2 stays inside that budget. At 21k tokens, the autoregressive models in this benchmark require 4.5 to 5 seconds per query; Mercury-2 needs under a second.
This is not really a Mercury-2 versus GPT comparison. It is a context length comparison. The right model depends almost entirely on what your retriever hands the generator.
The Decision Rule
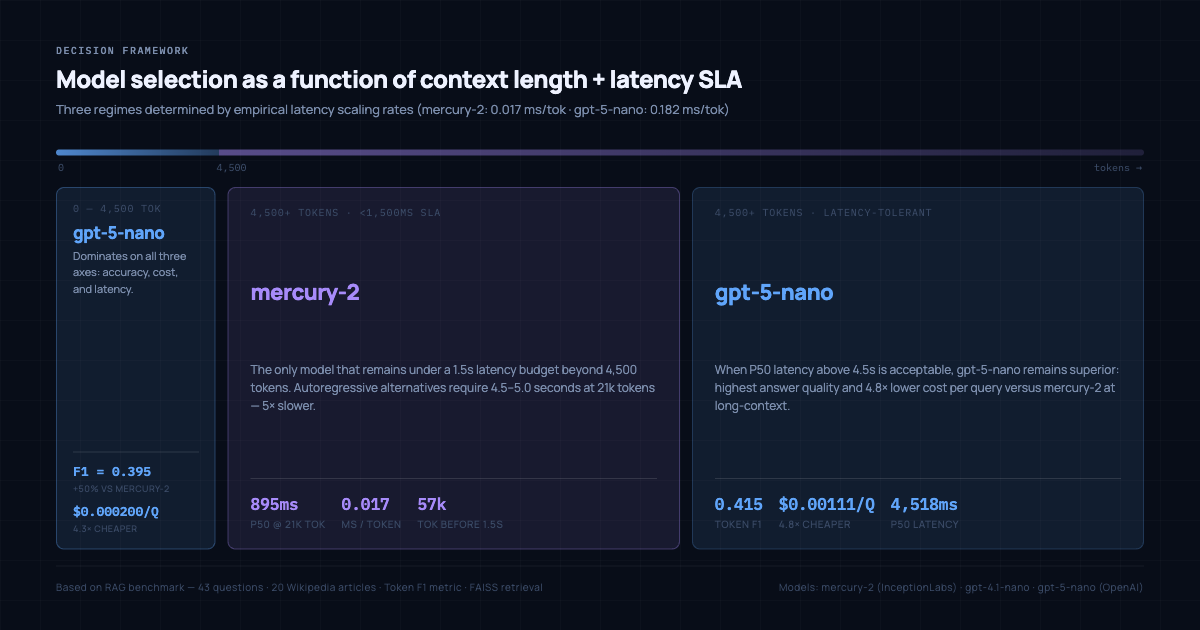
Based on empirical scaling rates measured across both context conditions, the decision breaks into three clean regimes:
0 to 4,500 tokens: GPT-5-nano Wins on all three axes at standard context: highest accuracy (F1=0.395), lowest cost ($0.000200/Q), and adequate latency. Mercury-2 is slower and less accurate in this range.
4,500+ tokens with a strict latency SLA: Mercury-2 The only model in this benchmark that remains under 1,500ms at long context. Autoregressive alternatives require 4.5 to 5.0 seconds at 21k tokens. If a hard latency requirement and a long retrieval window are both present, Mercury-2 is the only viable option.
4,500+ tokens with latency flexibility: GPT-5-nano When the 4.5 second wait is acceptable, GPT-5-nano still wins on answer quality (F1=0.415) and costs 4.8x less than Mercury-2 at long context. The right fit for batch processing, async pipelines, or workflows without a strict time constraint.
Caveats Worth Noting
Retrieval strategy matters as much as model selection. Aggressive chunking that tops out at 3k tokens means you never enter Mercury-2's performance territory. Full-document retrieval or multi-hop reasoning with long passages buys directly into its latency advantage.
Mercury-2 carries a higher cost at long context. At $0.005303 per query and 21k tokens, cost accumulates quickly at volume. GPT-5-nano at equivalent context costs less than a quarter as much. The economics only shift in Mercury-2's favor when a strict latency SLA is genuinely non-negotiable.
This benchmark used small-scale models. Mercury-2, GPT-4.1-nano, and GPT-5-nano are budget-tier models. Larger models will have different absolute accuracy and latency profiles, but the architectural relationship between diffusion and autoregressive scaling should remain consistent.
Takeaway
The default framing in LLM evaluations is which model produces better answers. In production RAG systems, the more useful question is what the latency profile looks like across the context lengths the pipeline actually uses.
At short context, GPT-5-nano is the easy answer: better accuracy, lower cost, and sufficient speed. At long context with a strict latency budget, Mercury-2's diffusion architecture becomes uniquely valuable. It is the only model in this benchmark that stays responsive as context scales, and the 5x latency gap at 21k tokens is large enough to be architecturally meaningful.
The crossover sits at approximately 4,500 tokens. Knowing where a given system lands relative to that line makes model selection considerably more straightforward.
Benchmark methodology: 43 Q&A pairs, FAISS retrieval, all-MiniLM-L6-v2 embeddings, standard and long-context conditions evaluated separately. Token F1 scored SQuAD-style. Costs computed from token usage at published pricing as of February 2026.