Everything is RL: Automatically Creating Optimal Agents with Evolutionary Methods


The way most people build software with LLMs today is: write something, look at it, ask an LLM to make it better, look at it again. Vibecoding. It's fast, it's surprisingly effective, and it's still fundamentally local search guided by human intuition.
Human intuition is a bad guide for knowing if something actually got better. You can feel like an iteration was good without having moved the metric that matters. You can iterate eight times and end up with a more sophisticated-looking solution that scores lower than what you started with. I know this because I ran the experiment.
The Missing Ingredient: A Score
Every powerful optimization framework (gradient descent, RLHF, evolutionary algorithms, A/B testing) shares one prerequisite: a scalar signal that tells you whether a candidate is better or worse than what you had before. Remove that signal and you're left navigating by aesthetics. You keep what looks good. You discard what feels wrong. Optimization needs a target; editing doesn't.
The deeper insight behind RL isn't about neural networks or policy gradients specifically. Once you can define what "good" means precisely enough to measure it, you can automate the search for good. The more expressive and accurate your reward signal, the more you can offload the improvement loop to something that doesn't get tired or run out of time.
This applies to building agents just as much as training models. An agent is a program. Improving it is a search problem. The interesting question is what's doing the searching.
Background: Evolutionary Algorithms
Evolutionary algorithms are a family of optimization methods that take inspiration from biological evolution. The core loop is simple: maintain a population of candidate solutions, evaluate each one against some fitness function, keep the best performers, generate new candidates by mutating or recombining the survivors, and repeat.
The power of this approach is that it doesn't require the search space to be differentiable, convex, or even well-understood. You just need two things: a way to generate new candidates from existing ones, and a way to score them. Selection pressure does the rest. Over generations, the population drifts toward regions of the search space that score well, with diversity maintained by mutation and recombination keeping the search from collapsing into a single point.
Evolutionary algorithms have historically been applied to things like neural architecture search, hyperparameter tuning, and combinatorial optimization. The limitation was always the mutation operator: generating new candidates required either random perturbation (slow, mostly bad) or hand-crafted domain-specific operators (requires expertise, doesn't generalize).
LLMs change this. FunSearch (DeepMind, 2023) was the first system to demonstrate this at scale: pairing a frozen LLM with a programmatic evaluator and an island-based evolutionary loop to discover new solutions to open mathematical problems. It produced the first genuinely new mathematical result from LLM-driven search.
AlphaEvolve: Using LLMs as Mutation Operators
In May 2025, DeepMind published AlphaEvolve, an evolutionary framework for code optimization that replaces traditional mutation operators with LLMs. The key insight: LLMs understand the structure and semantics of code, so they can propose mutations that are much more targeted and meaningful than random perturbations. Given an existing program and its score, an LLM can reason about why the program might be underperforming and suggest a specific structural change to address it.
AlphaEvolve pairs this with two ideas from the evolutionary algorithms literature:
Island model: Multiple populations evolve independently in parallel. Periodically, the best program from one island migrates to another. This prevents premature convergence — each island can explore a different region of the solution space, and migration spreads successful strategies once they're found.
MAP-Elites: A quality-diversity archiving scheme that maintains a grid of elite programs across behavioral dimensions (in code, things like number of functions, complexity, length). Rather than keeping only the single best program, MAP-Elites keeps the best program for each region of behavior-space. This preserves diversity in the population even as scores improve, giving the LLM mutation operator a richer and more varied set of examples to draw from.
The result is a framework that combines the structured reasoning of LLMs with the population diversity and selection pressure of evolutionary search. OpenEvolve is an open-source implementation of AlphaEvolve's architecture. The MAP-Elites + LLM combination specifically was validated in QDAIF (ICLR 2024), which showed that maintaining a quality-diversity archive rather than just tracking the single best solution produces richer, more varied populations for the LLM to draw from.
Applying This to LangGraph Agents
GraphEvolve is an adaptation of OpenEvolve specialized for evolving LangGraph agent pipelines. The structure is the same: island model for parallel populations, MAP-Elites archiving keyed by graph topology (number of nodes), and an LLM mutation operator that sees the current best agent, its score, and diverse examples from the archive before producing a new candidate.
The mutation LLM's job is not to follow a fixed recipe. It sees the task description, the current agent code, the score that code achieved, and a few examples of structurally different agents that have been tried. It then proposes a rewrite: a complete run_agent function that it believes will score higher. The evolutionary machinery handles everything else: running candidates in parallel, evaluating them against the reward function, updating the population, migrating between islands.
The LLM can suggest adding a new node, reordering the graph, changing which tools get called on which tickers, adding a scoring or prioritization step, or restructuring the synthesis prompt. Because it generates whole programs rather than line-level diffs, it's free to make structural changes that incremental editing would never propose.
A Concrete Test: Adversarial Portfolio Research
To test whether this actually beats manual iteration, I built an adversarial portfolio research task and ran both approaches with the same LLM (gpt-5-nano).
The task: thirteen fictional stock tickers, a 35-unit tool budget, and a reward function based on simulated 12-month forward returns. The agent calls research tools (screen_universe, get_financials, get_news, get_analyst_ratings, get_insider_activity) and produces BUY/HOLD/SELL recommendations. Calling every tool on every ticker costs roughly 144 units, so the agent has to decide which companies are worth investigating deeply.
The task was designed to reward tool-calling strategy rather than surface-level pattern matching:
-
Hidden gem (RVSP): Mediocre surface metrics (Hold consensus, only 8 analysts). But
get_newsreveals a $2.4B exclusive government contract, andget_insider_activityshows $28.2M in net buying by executives. Forward return: +250%. An agent ranking by EPS growth puts RVSP near the bottom. -
Traps (CLRN, CSCX, PTHR): Companies that look attractive on screening (high revenue growth, Buy consensus) but are disasters. CLRN has an FDA rejection and class action lawsuit buried in its news. CSCX has -$340M free cash flow and executives dumping $45M in shares. Getting these wrong is expensive.
-
Decoys (ORNX, KYMF): Tickers with the same surface profile as RVSP (low analyst coverage, industrial sector, Hold consensus) but boring tool output, specifically to break heuristics like "low analyst count means investigate deeper."
Human iteration: Start with a naive 2-node LangGraph (screen by EPS growth, ask LLM to produce BUY/HOLD/SELL). Each iteration gives the LLM the current code and current score, asks it to improve the agent, evaluates the result. 8 rounds. This is the vibecoding workflow — and corresponds to what the literature calls sequential verbal refinement, as formalized in Reflexion and SELF-REFINE (both NeurIPS 2023).
GraphEvolve: Two seed agents (the naive EPS-ranker, and a second that calls financials and analyst ratings for all tickers). Evolutionary search with 8 mutation candidates per generation, 3 islands, patience of 15 generations, run for 15 total generations.
Results
| Approach | Starting score | Best score |
|---|---|---|
| Human iteration (8 rounds) | 0.5683 | 0.5683 |
| GraphEvolve (15 generations) | 0.4332 / 0.6176 | 0.9970 |
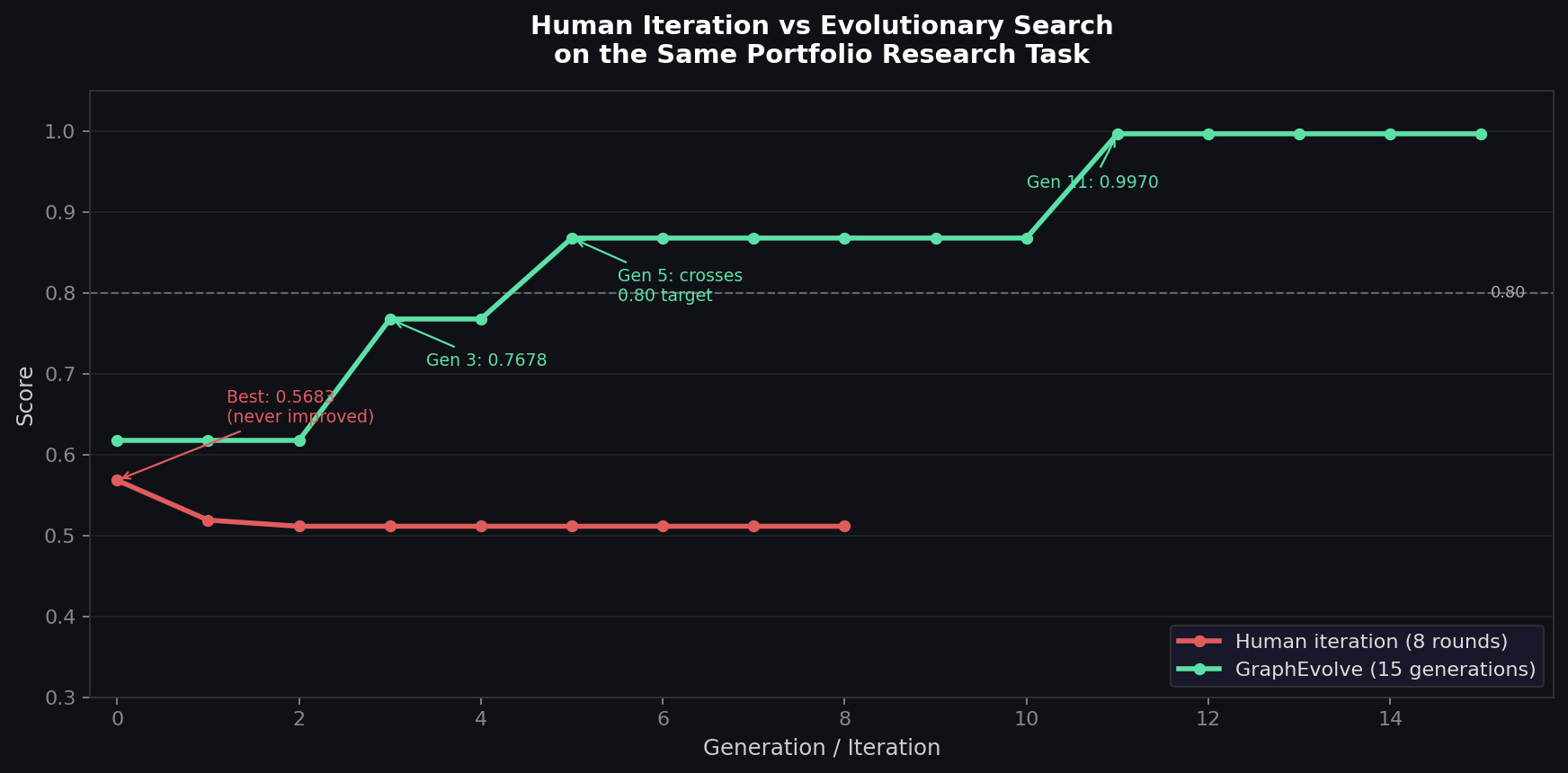
The human iteration trajectory: 0.5683 → 0.5190 → 0.5114 → 0.5114 → 0.5114 .... The first rewrite made the score worse. Every subsequent rewrite converged on a slightly different variant of the same EPS-rank strategy. The best result was the starting code.
GraphEvolve's trajectory tells a different story: 0.62 → 0.62 → 0.77 → 0.77 → 0.87 → ... → 0.997. It crossed the 0.80 target at generation 5 and reached near-perfect (0.9970) at generation 11, through a series of structural discoveries spread across multiple generations. Early generations found a prioritization layer that neither seed had. Later generations learned to specifically target the hidden gem and traps by calling the right tools on the right tickers. The score didn't improve smoothly — it plateaued, then jumped, then plateaued again — which is the expected pattern when the search is exploring a space where most mutations are neutral but occasional ones unlock a qualitatively better strategy.
This is the core failure mode of local search on a task that requires structural discovery. The best solution requires nodes and tool-calling logic that the seeds didn't contain. Iteration builds on what it was given. Population-based search with parallel mutations and selection pressure explores sideways until it stumbles onto something better, then propagates it. ADAS (ICLR 2025) is the closest peer in this space — it also evolves Python agent code using an LLM — but uses a sequential archive rather than a parallel island population, making it more susceptible to converging on one design archetype early. AFlow (ICLR 2025) takes a similar approach using MCTS over agent workflows and reports +5.7% over hand-designed baselines. Neither uses explicit population diversity mechanisms.
The Real Reason to Write Evals
Evals are usually framed as a quality gate: you write them to catch regressions, verify behavior, or get a safety signal before deployment. All of that matters.
There's a second reason that gets less attention. Without a score, systematic improvement is impossible. You can only edit by feel.
A reward function precise enough to score a candidate agent (even imperfectly, even approximately) unlocks the entire optimization infrastructure described above. You can run more candidates, apply selection pressure, maintain diversity. The quality of your eval sets the ceiling on what you can find. A noisy eval still tells you something. No eval leaves you navigating by aesthetics indefinitely.
The hardest part of this experiment wasn't the evolutionary machinery, which is a few hundred lines of Python. The hard part was writing a reward function that actually captured what a good agent looks like. For the portfolio task, that meant working through what distinguished a genuinely good agent from a mediocre one: does it discover hidden signals that surface screening misses? Does it know when to distrust stale analyst consensus? Does it avoid burning its budget on low-information tool calls? Writing that function forced a precision about the objective that vibecoding never requires and rarely achieves.
That precision is the prerequisite for automated optimization across the board. RLHF works because human preference can be distilled into a reward model. AlphaCode works because competitive programming has an automated judge. Test-time compute scaling works because you can score reasoning chains against verified answers. EUREKA (NVIDIA, ICLR 2024) ran the same experiment in the opposite direction: rather than evolving the agent with a fixed reward function, it evolved the reward function with a fixed RL training loop — and beat human-expert reward designs on 83% of 29 robotics tasks. The mechanism is identical; what you put on each side of the eval depends on which part of the system you're trying to improve. The pattern is always the same: make the objective legible, then run the search. Once a model is capable enough, the bottleneck in building better systems usually shifts from capability to specification. An eval is how you answer "what exactly do you want?" precisely enough to act on it.
What This Doesn't Mean
Vibecoding is the right starting point for most things. When you're figuring out what the correct structure even is, iteration by feel is appropriate. You don't have an eval because you don't know yet what you're measuring.
The argument is about what comes next. Once you have a rough shape of the thing, writing an eval changes the nature of improvement entirely. You go from asking an LLM to make something better and judging by eye, to running a structured search over the space of programs with selection pressure toward what actually works.
The vibecoding loop is fine as a starting point. Treat it as the manual version of something that can be automated, once you define the objective precisely enough to measure it.