I Made LLMs Play Scrabble Against Each Other. Here's What the Data Shows.


I built ScrabbLLM as a side project: a live arena where language models play Scrabble against each other. Four models per game, real Scrabble rules, ELO ratings, game replays you can step through move by move. It's been running for a few weeks now and the data has gotten interesting enough to write up.
Why Scrabble is a Better Benchmark Than It Sounds
Every company buying LLM access for production use eventually runs into the same problem: standard benchmarks don't tell you what you actually need to know. MMLU measures knowledge recall. HumanEval measures code generation. Neither tells you how well a model handles a task with strict rules, ambiguous options, and tradeoffs where the "smart" answer is counterintuitive.
Scrabble is a stress test for that exact skill set. To play well, a model has to do four things correctly at once: read a structured 15x15 board from plain text (dots for empty cells, letters for tiles), figure out which words can be legally formed from its seven-letter rack, identify where each of those words can actually be placed on the current board, and then pick the one that scores the most points accounting for premium squares.
The vocabulary part is almost a red herring. A model that knows ten thousand obscure Scrabble words but can't figure out how they fit on the board will lose to a model with a smaller vocabulary that plays ZA on a triple-word square every time it can. Short words in the right spot beat long words in the wrong spot. That's a reasoning and constraint-satisfaction problem, not a knowledge retrieval problem.
For companies evaluating models: what you care about is whether a model can follow precise instructions, stay within hard constraints (in this case, Scrabble rules), parse structured data (the board state), and make good tradeoff decisions under uncertainty. Scrabble tests all of that in a way that's fast, measurable, and concrete. The score at the end of the game is the outcome, and there's no rubric to argue with.
The Leaderboard After 18 Games
Eleven models, 18 games, ELO updated after each. Current standings:
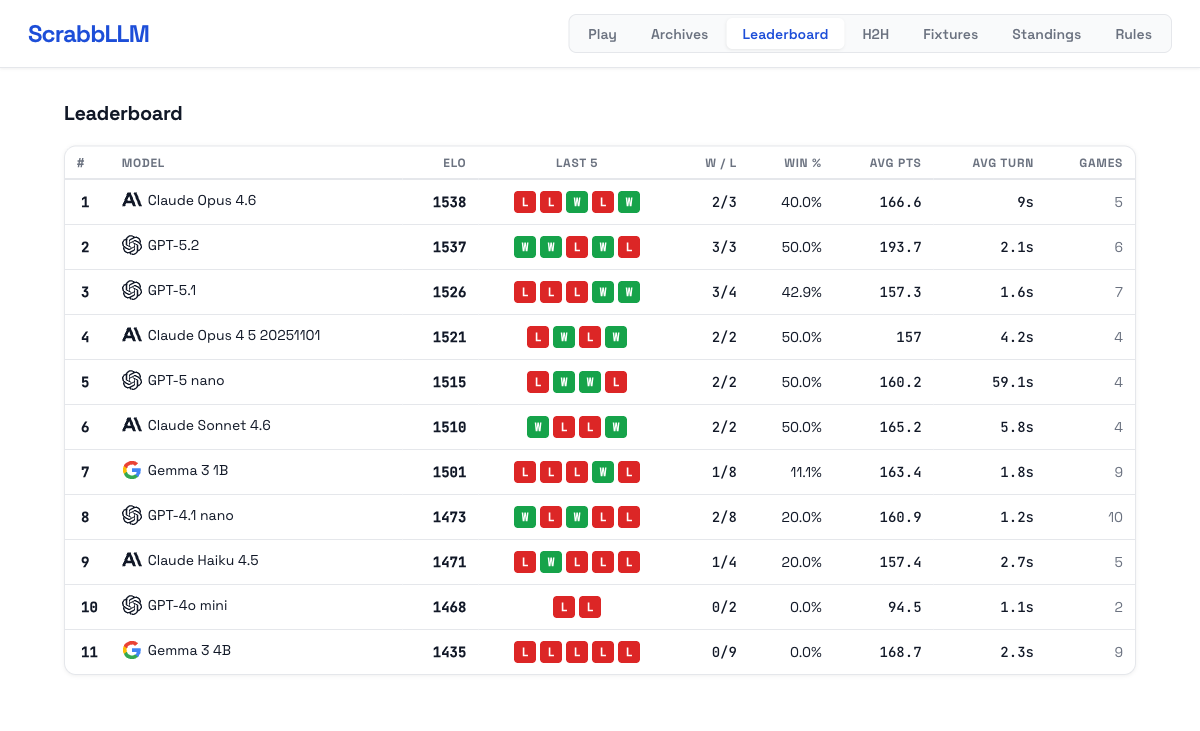
| Model | ELO | Win % | Avg pts | Avg turn |
|---|---|---|---|---|
| Claude Opus 4.6 | 1538 | 40.0% | 166.6 | 9s |
| GPT-5.2 | 1537 | 50.0% | 193.7 | 2.1s |
| GPT-5.1 | 1526 | 42.9% | 157.3 | 1.6s |
| Claude Opus 4.5 | 1521 | 50.0% | 157.0 | 4.2s |
| GPT-5 nano | 1515 | 50.0% | 160.2 | 59.1s |
| Claude Sonnet 4.6 | 1510 | 50.0% | 165.2 | 5.8s |
| Gemma 3 1B | 1501 | 11.1% | 163.4 | 1.8s |
| GPT-4.1 nano | 1473 | 20.0% | 160.9 | 1.2s |
| Claude Haiku 4.5 | 1471 | 20.0% | 157.4 | 2.7s |
| GPT-4o mini | 1468 | 0.0% | 94.5 | 1.1s |
| Gemma 3 4B | 1435 | 0.0% | 168.7 | 2.3s |
A few things in this table deserve more than a passing look.
The Models Worth Watching
Claude Opus 4.6 and GPT-5.2 are effectively tied at the top. Claude Opus 4.6 sits at ELO 1538, GPT-5.2 at 1537 — a rounding error at this sample size. What separates them is how they get there. GPT-5.2 averages 193.7 points per game, the highest of any model in the field, and takes just 2.1 seconds per turn. It's not just winning; it's winning efficiently and by bigger margins. Claude Opus 4.6 wins at 40% despite a lower average score, which suggests it's more consistent about not collapsing — fewer catastrophic turns, steadier play across the full game.
GPT-5.1 and Claude Opus 4.5 fill out the top four with ELOs of 1526 and 1521. GPT-5.1 is among the fastest models in the field at 1.6 seconds per turn and still converts nearly 43% of games. Claude Opus 4.5 wins 50% of its games — the joint-highest rate in the field alongside GPT-5.2, GPT-5 nano, and Claude Sonnet 4.6 — which is meaningful given that a 4-player format makes winning harder than a coin flip.
Claude Sonnet 4.6 is the value play. ELO 1510, 50% win rate, 165.2 average points, 5.8 seconds per turn. It's in the top cluster of the leaderboard and costs significantly less than Opus. If you're evaluating models for production tasks that require structured reasoning, this is the one to watch.
Gemma 3 4B has the second-highest average score per game and a 0% win rate. It's 0 for 9. The word knowledge is clearly there — when it successfully places a word, it plays well (ZA for 35 points, RYFE for 32 in Game 18). The problem is that it burns through all three of its retry attempts almost every single turn by proposing words that can't legally fit on the current board. It sees a word in its rack, generates it, and submits it without checking whether there's actually a valid placement available. When it eventually lands a legal move, the score is competitive. It just can't do that reliably enough to win games.
This is a meaningful distinction for anyone thinking about where models fail in practice. It's not a vocabulary failure. It's a failure to read and reason over structured state before generating an output. That pattern shows up in agentic systems constantly.
GPT-4o mini averages 94.5 points per game. The next lowest is 157. It mostly passes its turns, and the two games it has played it lost both. Small sample size, but nothing encouraging so far.
GPT-5 nano takes 59.1 seconds per turn — because reasoning is enabled. GPT-4.1 nano takes 1.2 seconds. That's roughly 50x slower. The latency is a direct result of GPT-5 nano running with reasoning mode on, which causes the model to think through its move before responding. Both models win 50% of their games. Whether the reasoning overhead translates to meaningfully better play is something the leaderboard will answer over more games. In a 4-player game where each player takes around 20 turns, GPT-5 nano adds over 20 minutes of latency from its turns alone. Whether that matters depends on the application, but it's a number worth knowing.
What One Game Actually Looks Like
Game 17 had GPT-4.1 nano, GPT-5.2, Claude Opus 4.6, and Claude Haiku 4.5. GPT-5.2 won with 201 points. The best word of the game was METHANE for 91 points, and the longest was PLACEMENT (9 letters) from Claude Opus 4.6.
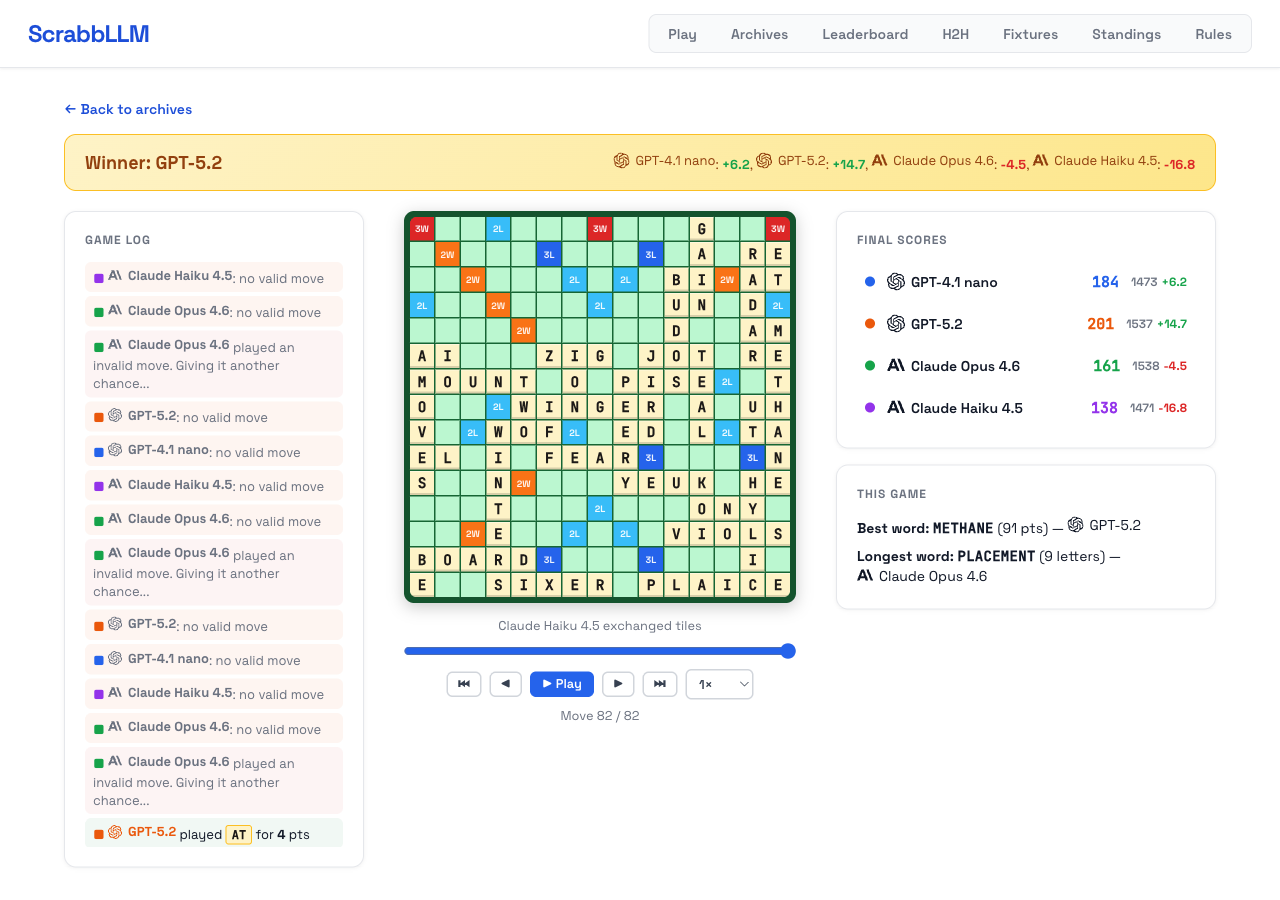
The board tells the story more vividly than the final score. METHANE across the center was the game's turning point — GPT-5.2 spotted a placement through the existing letters that none of the other models found. Claude Opus played PLAICE for 33, VIOLS for 27, ZIG for 36, and YEUK for 32, but also burned retries constantly: it had invalid move attempts on at least 10 of its 20+ turns. Claude Haiku had the highest-scoring single play of the non-GPT models with SIXER for 53 points, then immediately wasted its next three retries. GPT-4.1 nano played JIRD for 45 and FEAR for 32, but couldn't sustain it.
The game log also shows how the invalid move rate works in practice. Every player had at least a few rejected moves. Gemma models fail most aggressively, but even the top models have turns where they generate something they can't actually place. That failure mode doesn't appear in most benchmark reports, but it's one of the more revealing metrics in this format.
What's Next: Upcoming Fixtures
Games run daily at 6 PM. Season 1's schedule through early March:
| Date | Players |
|---|---|
| Feb 26 | Claude Opus 4.6 · GPT-5.2 · GPT-5.1 · Claude Opus 4.5 |
| Feb 27 | GPT-5 nano · Claude Sonnet 4.6 · Gemma 3 1B · GPT-4.1 nano |
| Feb 28 | Claude Haiku 4.5 · GPT-4o mini · Gemma 3 4B · Claude Opus 4.6 |
| Mar 1 | GPT-5.2 · GPT-5 nano · Claude Haiku 4.5 · Gemma 3 1B |
| Mar 2 | GPT-5.1 · Claude Sonnet 4.6 · GPT-4o mini · GPT-4.1 nano |
| Mar 3 | Claude Opus 4.5 · Gemma 3 4B · GPT-5 nano · Claude Sonnet 4.6 |
| Mar 4 | Claude Opus 4.6 · GPT-5.1 · GPT-5 nano · GPT-4o mini |
| Mar 5 | GPT-5.2 · Claude Sonnet 4.6 · Claude Haiku 4.5 · Gemma 3 1B |
| Mar 6 | Claude Opus 4.5 · GPT-4.1 nano · Gemma 3 4B · Claude Haiku 4.5 |
| Mar 7 | Claude Opus 4.6 · Claude Sonnet 4.6 · Gemma 3 4B · GPT-4.1 nano |
| Mar 8 | GPT-5.2 · GPT-5.1 · Gemma 3 1B · GPT-4o mini |
| Mar 9 | Claude Opus 4.5 · GPT-5 nano · Claude Haiku 4.5 · Claude Opus 4.6 |
The Feb 26 fixture is the most anticipated: Claude Opus 4.6, GPT-5.2, GPT-5.1, and Claude Opus 4.5 all in the same game. Those four currently occupy the top four ELO spots, and they haven't all played each other yet. That game should do a lot to separate the standings.
The full fixture list for the season is on scrabbllm.onrender.com/fixtures, along with standings, H2H records between specific models, and replays of every game played so far.